基于大模型的移动应用合规检测系统开发记录
基于大模型的移动应用合规检测系统开发记录
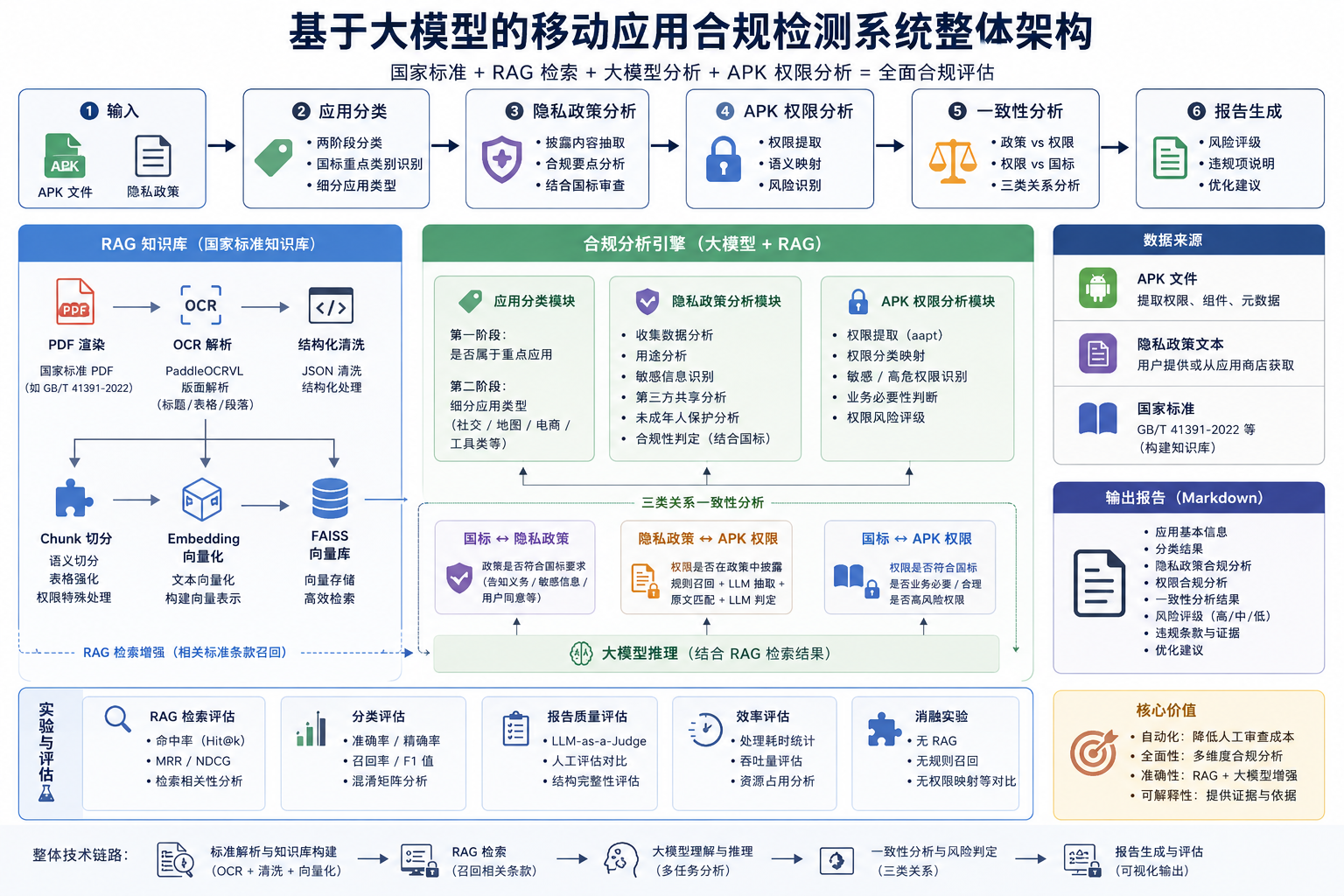
最近一直在做一个和“大模型 + RAG + 移动应用隐私合规检测”相关的项目。
这个项目从最开始的简单想法,到后面慢慢扩展成完整的实验系统,其实经历了很长时间的迭代。
现在回头看,已经不仅仅只是一个“调用大模型”的脚本了,而是一个包含:
- 标准知识库构建
- RAG 检索
- 应用分类
- 隐私政策分析
- APK 权限分析
- 自动报告生成
- 实验评估
- 消融实验
的完整研究型项目。
一、项目最开始的想法
一开始做这个项目,其实是因为发现:
现在很多移动应用虽然都有隐私政策,但真正认真阅读的人很少。
而且很多应用存在:
- 权限申请过多
- 隐私政策披露不完整
- 实际行为和声明不一致
- 敏感信息处理不规范
这些问题。
于是后面就开始思考:
能不能利用大模型和 RAG,把国家标准、隐私政策和 APK 权限结合起来,自动做合规分析?
后来整个项目就慢慢成型了。
二、项目整体目标
整个系统主要围绕三个问题展开:
1. 应用分类识别
系统需要先判断:
一个应用到底属于什么类型。
这里参考的是:
1 | GB/T 41391-2022 |
中的重点应用类别。
系统会结合:
- 应用简介
- 隐私政策
- 国标定义
- RAG 检索结果
自动完成分类。
2. 隐私政策合规审查
第二部分是分析隐私政策本身。
例如:
- 是否明确说明收集的数据
- 是否说明用途
- 是否涉及敏感信息
- 是否存在第三方共享
- 是否涉及未成年人规则
然后结合国家标准做合规判断。
3. APK 权限一致性分析
这一部分主要是:
把 APK 权限和隐私政策进行比对。
例如:
- 是否申请了未披露权限
- 是否存在超范围申请
- 权限和业务是否匹配
- 是否属于高风险权限
这一部分后面做得其实比较复杂。
三、项目技术路线
整个系统后面采用的是:
1 | 国家标准 → RAG知识库 → 大模型分析 → 自动生成报告 |
这样的整体链路。
四、RAG 知识库构建
这一部分其实是整个系统最麻烦的部分之一。
因为国家标准 PDF 本身结构并不好处理。
所以后面单独做了一整套:
- PDF 渲染
- OCR 解析
- JSON 清洗
- chunk 切分
- embedding 构建
- FAISS 向量化
流程。
1. PDF 渲染
首先把 PDF 渲染成高清图片。
这样后面的 OCR 才更稳定。
2. OCR 解析
后面使用:
1 | PaddleOCRVL |
做版面解析。
包括:
- 标题
- 表格
- 附录
- 段落结构
全部提取成结构化内容。
3. chunk 构建
这一部分其实调了很久。
因为:
chunk 太小会丢上下文。
chunk 太大又会影响检索精度。
后面针对:
- 权限
- 类别
- 敏感信息
- 附录
做了强化切分。
4. 向量化
最后把 chunk 写入:
1 | FAISS |
形成 RAG 检索库。
五、应用分类模块
后面单独做了应用分类模块。
采用的是“两阶段分类”。
第一阶段
先判断:
应用是否属于国标中的重点类别。
第二阶段
如果属于重点类别:
再进一步细分具体类型。
例如:
- 社交
- 地图导航
- 电商
- 工具类
等等。
六、多任务合规分析
后面整个系统核心其实是:
三类关系分析。
1. 国标 ↔ 隐私政策
分析隐私政策是否符合国家标准。
包括:
- 告知义务
- 敏感信息
- 第三方共享
- 用户同意
- 未成年人规则
等控制点。
2. 隐私政策 ↔ APK 权限
这一部分主要分析:
权限是否在隐私政策中被披露。
后面采用的是:
1 | 规则召回 + LLM 抽取 + 原文匹配 + LLM 判定 |
的混合方案。
3. 国标 ↔ APK 权限
这一部分会进一步判断:
某个权限到底:
- 是否业务必要
- 是否合理
- 是否属于高风险权限
最后给出风险等级。
七、实验部分
这个项目后面其实不仅仅是功能实现。
还做了很多实验。
包括:
- RAG 检索评估
- 分类评估
- 报告质量评估
- 效率评估
- 消融实验
这一部分对论文帮助非常大。
八、开发过程中遇到的问题
其实整个项目踩了很多坑。
1. OCR 解析稳定性
不同 PDF 格式差异很大。
有些:
- 表格会错位
- 标题层级会丢失
- 附录结构很混乱
后面做了大量清洗。
2. chunk 切分问题
最开始直接固定长度切分。
结果:
RAG 检索效果很差。
后面改成:
- 语义结构切分
- 表格强化
- 权限特殊处理
效果才慢慢稳定。
3. 权限语义映射
这一部分其实很难。
因为:
很多权限并不一定能直接映射到某种业务。
尤其是:
- 厂商权限
- 第三方 SDK 权限
后面增加了弱语义推断。
4. 大模型稳定性
不同模型输出风格差异非常明显。
后面为了保证:
- 输出格式稳定
- 报告结构统一
又做了很多 prompt 约束。
九、目前项目的整体状态
目前整个系统已经能够完成:
- 标准解析
- 知识库构建
- RAG 检索
- 应用分类
- 三类合规分析
- 自动生成 Markdown 报告
- 实验评估
已经基本具备完整研究型原型系统的能力。
十、后续准备继续优化的方向
后面准备继续完善:
1. 配置系统统一化
目前很多:
- 路径
- 模型名
- 参数
还写在脚本里。
后面准备统一:
1 | config.yaml |
管理。
2. FastAPI 接口化
目前主要还是:
批处理脚本。
后面准备做:
- FastAPI 后端
- Web 页面
- 文件上传
- 报告下载
让整个系统更像真正的平台。
3. 模块进一步解耦
目前部分代码:
- LLM 调用
- IO
- 文本清洗
还有重复逻辑。
后面准备继续模块化。
十一、总结
这个项目其实是目前做过最复杂的一个项目之一。
从最开始的想法,到后面:
- RAG
- OCR
- 向量检索
- 权限分析
- Prompt
- 消融实验